
What is Googlebot? – Getting to Know Google’s Crawler
Google crawling and indexing are terms you have probably heard while diving into the deeply dynamic waters of search engine optimization. You’ve also probably heard about Google’s search engine bots like its famous Googlebot.
But what is Googlebot? And how does Googlebot work in SEO?
For the analyst team at Radd, Google’s index is our lifeblood, and the same goes for internet marketing institutions worldwide. It is the foundation upon which our efforts are built. With that being said, we are going to take a deeper look into the technicalities of Google’s indexing process and explore the ways in which it affects the success of businesses and websites.
For businesses that want to expand their search performance and grow their online presence, understanding how Googlebot works can help.
What is Googlebot crawling and indexing, and how does it affect my site?
Googlebot is a special software, commonly referred to as a spider, designed to crawl its way through the pages of public websites. It follows a series of links starting from one page to the next, and then processes the data it finds into a collective index.
This software allows Google to compile over 1 million GB of information in only a fraction of a second. Online search results are then pulled directly from this index. A fun and easy way to think of it is as a library with an ever-expanding inventory. Googlebot is a generic term for the tools it uses to discover web content in both desktop and mobile settings.
With this in mind, then what is Googlebot in SEO terms?
The strategic optimization of webpages works to increase visibility amongst web search results. The way your website is mapped out via text links can greatly enhance the overall effectiveness of Googlebot’s crawl. Substantial SEO practices include optimization techniques geared toward both Googlebot and the search engine results pages (SERPs).
Ultimately, the more clear and concise your sitemap and content is, the more prominent your pages are likely to be overall.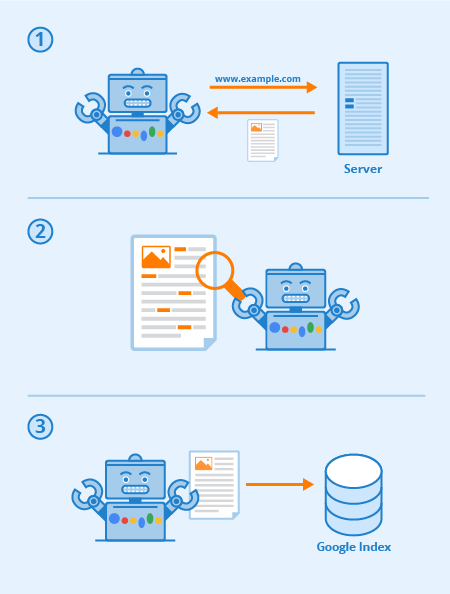
Every search engine (and many other websites) have bots, and Googlebot is Google’s. Googlebot is a crawling bot that in simple terms goes from link to link trying to discover new URLs for its index.
Here’s how Googlebot works: links are critical for allowing it to go from page-to-page (and they can be any kind of link too) – image links, nav-bar, anchor-text, and even links hidden with properly readable JavaScript.
When these pages are discovered their content is rendered by Googlebot and its content is read so that the search engine can determine its subject matter as well as its value to searchers. Proper SEO strategy means that sites with good structure, fast load times, and understandable content are easy for Googlebot to digest and can help a site’s SEO.
Via Seobility
What is website crawlability?
Crawlability refers to the degree of access Googlebot has to your entire site. The easier it is for the software to sift through your content, the better your performance within the SERPs will be.
However, it is possible for crawlers to be blocked, if not from your site as a whole, certainly from select pages. Common issues that can negatively affect your crawlability include complications with a DNS, a misconfigured firewall or protection program, or sometimes even your content management system. It should be noted that you can personally manipulate which pages Googlebot can and can’t read, but take extra care to ensure that your most important pages do not get blocked.
What can I do to optimize my site for Googlebot?
Here are a few tips and suggestions in regard to optimizing your website for the Googlebot crawler:
- Your content needs to be easily visible in a text browser, so don’t make it too complicated. Googlebot has a difficult time crawling sites that utilize programs such as Ajax and (sometimes) JavaScript. When in doubt, keep it simple.
- Use canonical pages to help Googlebot find the right version of duplicate pages. For many websites it’s common to have multiple URLs for the same page. Modern Googlebot is even able to know when this is happening but having tons of duplicate page across multiple URLs can sometimes confuse it, slow down it’s indexing speed, and reduce your crawl budget. That’s why canonicalizing is best-practice for SEO in most cases.
- Guide Googlebot through your site using your robots.txt file or meta robots tags. Blocking the crawler from unimportant pages will cause the software to spend its time on your more valuable content and help it understand your site’s structure. (In recent years Google has down-played the effect of robots.txt for blocking pages from the index which no longer works for certain, best practice is to use “no-index” directives instead)
- Fresh Content. Google loves fresh and relevant content. Updating old pages or creating new ones will spark the crawler’s interest. The more frequently you are crawled, the more chances you have to increase performance. However, this only applies so long as you make quality updates. Always make sure your copy is well-written and not overstuffed with keywords. Poorly written content will only have a negative effect.
- Internal Linking. Internal linking by way of anchor text links, or ATLs, helps direct the crawler through your site. A tightly consolidated linking system can make Googlebot’s crawl much more effective. You want to be deliberate when writing ATLs. Only link to pages that are relevant to your content or product, and make sure the destination cannot otherwise be accessed from the current page’s navigation bar.
- Submitting a sitemap. Sitemaps are files hosted on a site’s server that list all of the site’s URLs (or all of the one’s the site owners choose to include at least). Sitemaps are good for SEO since they give Googlebot an easy to find and easy to digest list of all of your most valuable pages. With a sitemap, sites will likely get indexed more quickly and more frequently.
The performance of your site within Google is a many-layered thing, and it is important to remember that Googlebot is always crawling.
The different kinds of Googlebots
According to Google all websites are likely going to be crawled by both Googlebot Desktop and Googlebot Smartphone. Variations on its crawlers that are designed to collect different information for different devices. When Google announced mobile-first indexing for its index in 2018, it meant that websites with mobile versions would have that version entered into its index by default – signaling to online businesses and websites that mobile traffic was becoming ever more dominant.
Googlebot uses different “user-agents” to mimic different devices or technologies so it can see how web content appears to those different softwares.
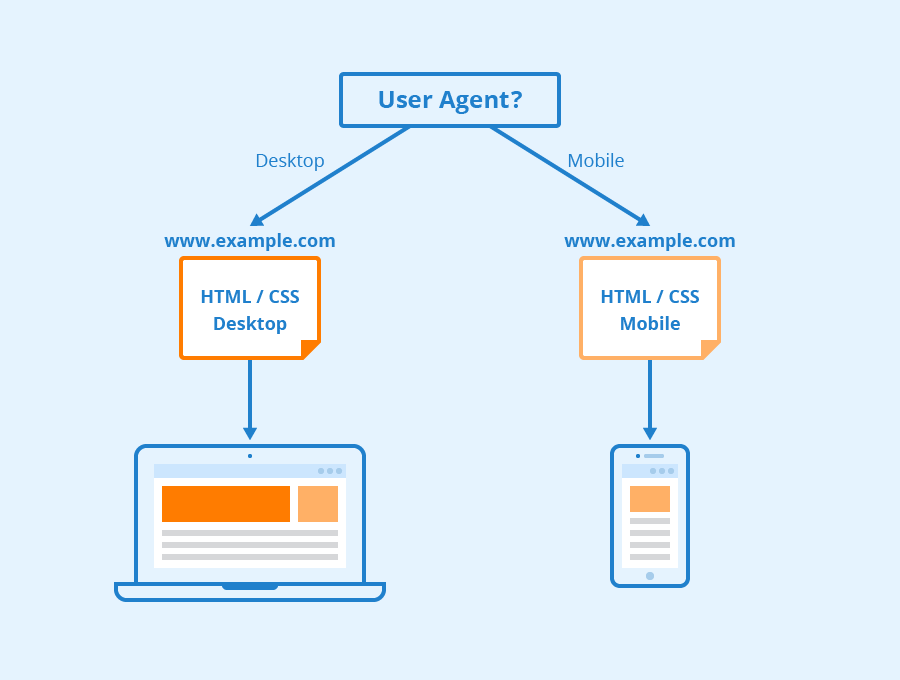
Via Seobility
What is Googlebot Smartphone? In fact, how many Googlebots are there?
Google has sixteen different bots designed for various forms of site rendering and crawling. The truth is that for SEO you rarely ever need to set up your site differently for any of these. Each of these bots can be handled different using your robots.txt file or your meta commands, but unless you specify directives for a particular bot, they will all be treated the same way.
Googlebot runs on Google’s Chromium rendering engine which is updated from time-to-time to ensure that it is capable of understanding modern website coding parameters and styles and to ensure that it can quickly render modern pages.
Googlebot’s Chromium has become what google calls an “evergreen” engine meaning that it will always run the latest Chromium based engine for rendering websites they way that the Chrome browser does (along with other user-agents for various other common web browsers). Google’s long-standing goal is to be able to render and understand websites and web pages the way that humans do, this means that Googlebot will understand pages much the same way that they appear in modern web browsers.
Learn More
So what is Googlebot in SEO? Contact us to get more info.
At Radd Interactive, our analyst team works to perform strategic optimizations that enhance a site’s performance as a whole, keeping in consideration Googlebot’s appetite for fresh, relevant, and easy-to-digest content.
Optimizing for the Googlebot crawler helps ensure your website is being crawled and indexed both thoroughly and efficiently for the best possible results.