
Google’s Index Coverage Report – Checking A Site’s Index Status
Businesses and marketers can see which of their pages have been indexed and can diagnose any problems with their site’s indexability using Google’s Search Console.
Google’s index coverage report can give webmasters a greater understanding of how their site is being viewed and crawled by Google, but it can also include a wide range of messages and warnings. Being able to Check Google index status and to fix any issue on your site is crucial to maintaining search engine optimization. Learning what these messages mean, and how you should respond to them will help to make sure that important parts of your site aren’t missing from search results and that your organic traffic isn’t being ruined by bad practices.
What is the coverage report?
Google’s index coverage report in Search Console is designed mainly for letting webmasters know which of their pages are in the search index, and which are not.
But the truth is that this tool offers a lot more information than just that. It shows the status of all a website’s pages that Google has visited – or tried to visit. Specifically URLs on your Search Console property that have been visited and crawled by Googlebot.
Here all of the pages are grouped by status along with a count of pages that have been “validated” by Google and added to the index, pages that have been excluded from the index, pages with major issues, and pages with warnings.
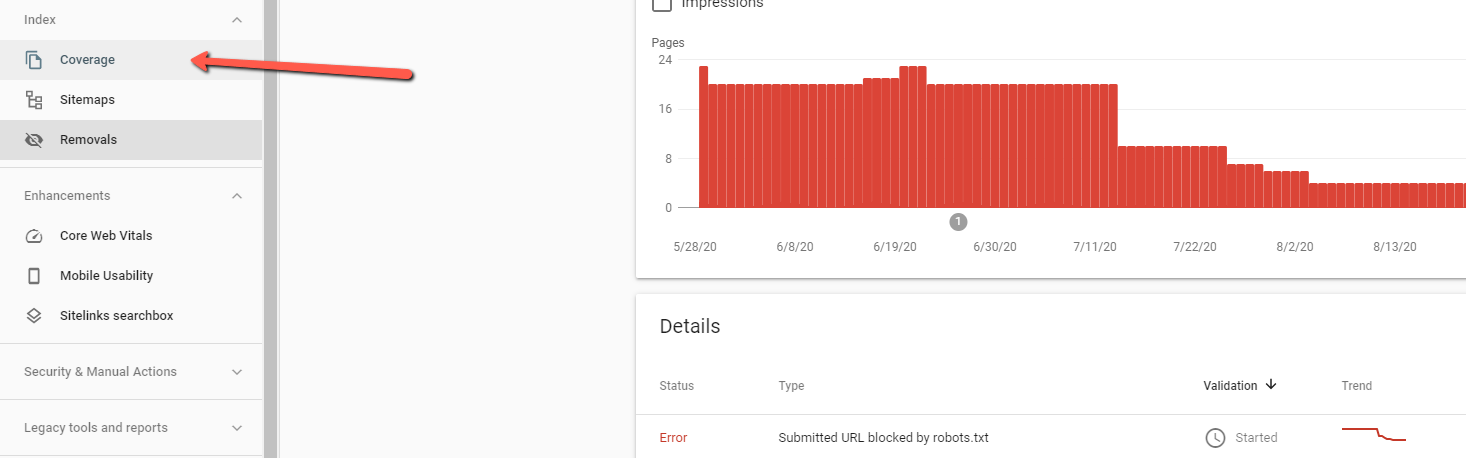
The “Summary Page” of the Google index report
Users can click on any one of the rows in the summary page to see all URLs with the same status/reason and more details about the issue.
This page also includes extra information like the Primary Crawler used for the site (specific type of Googlebot) and the date the report was last updated.
To access the Google index Coverage report, you first need to have and set-up a Search Console account. This free tool is designed to specifically give webmasters and business owners information on how their site is handled by Google. Find your site’s property in the console and then navigate to the “Coverage” report in the left-side navigation panel.
Checking Google index status
This report is very important for SEO since it gives businesses a way of seeing which of their pages have been indexed properly and whether or not their main content is available to searchers. Otherwise it’s largely just a guessing game of knowing whether people can find your site in search results.
So what should you look for in your index coverage report? Ideally you should see a gradually increasing count of valid indexed pages as your site grows. Particularly if you are continuously adding new content to your site, or if you are trying to monitor SEO for a new website.
For old websites, or businesses that have very consistent content – you shouldn’t necessarily expect to see any extreme changes (though slight up-and-down variation in the number of valid pages is normal).
If you see drops or spikes, there could be an issue with the indexability of your site. The status table in the summary page is grouped and sorted by “status” and the reason for the issue; you should fix your most impactful errors first.
How to use the index coverage report
Google’s index report is a great tool for webmasters and businesses to check their site’s health. Use this report to assess how your site is being indexed and whether Google is having any trouble understanding your pages, crawling individual URLs, or indexing the correct URLs.
This report gives a great birds-eye-view for what is being indexed properly, with the graph. Many SEOs and webmasters will visually scan this chart to check for a disproportionate amount of errors and warnings and then dig down from there. If you’re trying to check the Google index status of your site, you should do the same.
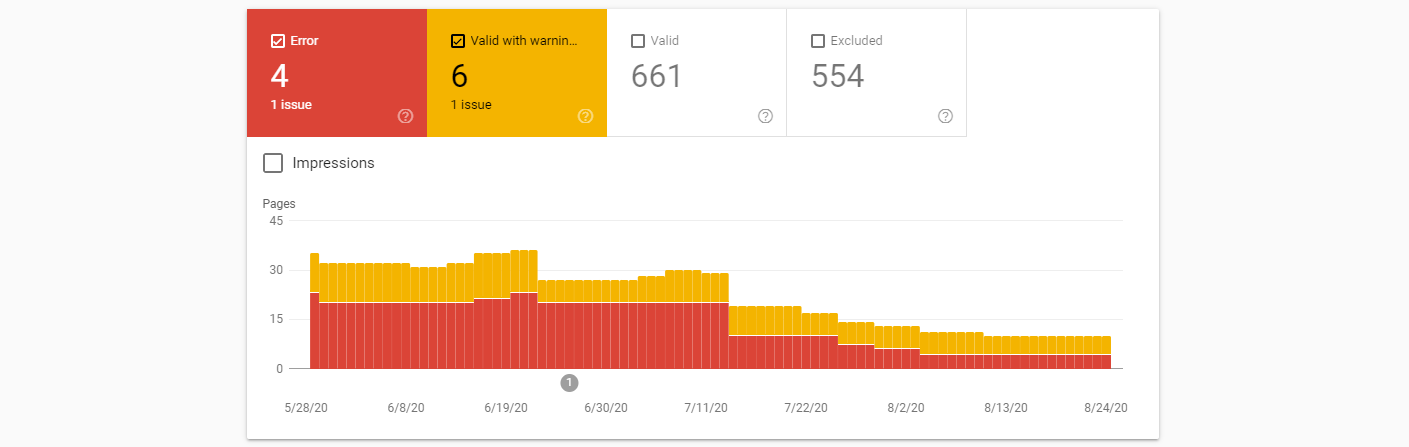
You should prioritize the errors shown here (demonstrated in red) and then look for explanations about what could be causing issues. Once those issues have been resolved you can also have your SEO team verify any “warnings” here and maintain a healthy amount of healthy, indexed, pages. The index coverage report in Search Console doesn’t provide any tools or developer resources for fixing these issues – this report is used only for checking and monitoring.
A good way to work with the index coverage reports “errors” tab is to work through a technical SEO audit checklist to try and isolate any bad-practices on your site. Thankfully the index coverage report will group URLs together by individual messages, so you can try to determine shared qualities and narrow-down any common elements that might be causing issues.
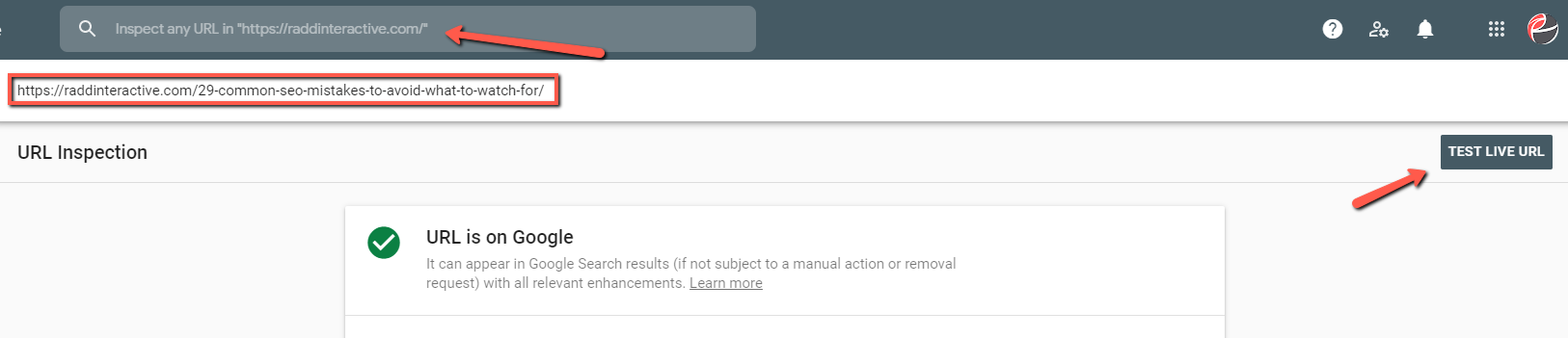
You can also use the URL Inspection tool in Search Console to get specific information on common issues and problems. For even more in-depth information, you can “Test Live URL” to try and discover any problems with a URL.
Have your webmaster or web developer make any fixes and then use the “Validate Fix” option in Search Console to have Google recrawl your pages and update the index once issues have been resolved.
Here’s every message in the index coverage report
There’s a lot of potential messages that you can see when you check your Google index status – so we’ve made a list of all of them. The truth is though that you’ll most likely see only a handful of these, and most of the time the messages don’t require any action or fixes – they’re just communicating to you the status of your site.
Read through to better understand all of the messages you can find in the index coverage report.
Server error (5xx): This is a server level error which means that the page could not be loaded. Google won’t add these pages to the index in this case, which means for high-value content and important pages this error can have serious effects on SEO.
Submitted URL blocked by robots.txt: This message is somewhat self-explanatory. This message appears in the “Error” tab of the Google index coverage report if you’ve specifically asked for the page to be indexed (either in the URL inspection tool or in your sitemap) – this gives it contradictory requests. In cases where you don’t want the page to be indexed this message is harmless, otherwise you may have to update your robots.txt file.
Submitted URL marked ‘noindex’: Similar to the error message above. A request has been made to index the page, but the on-page robots command (with either a meta tag or in the HTTP header) is requesting no index.
Submitted URL seems to be a Soft 404: This message is shown for pages that have been submitted to the index but appear as a “soft” 404 error when Googlebot attempts to crawl them. These pages can be left alone if the “empty” status or “out of stock” status is just temporary – but it would be a good idea to check these pages to make sure they have valuable content.
In rare cases, a page that is valuable to your site might accidentally look like a soft 404 if the page appears blank or almost blank to Google if it has very low-value, thin content.
Submitted URL returns unauthorized request (401): The status 401 message is for “unauthorized” pages, which indicates that authentication credentials are required. Usually for backend parts of a domain like login pages, account pages, staging-sites, etc. If these pages have limited access, then their SEO value is likely limited as well. Reassess whether these should be included in a sitemap and remove them in order to improve your crawl budget.
Submitted URL not found (404): For pages that have been submitted for indexing, via the sitemap, that are returning a 404 error. These pages should be removed from the sitemap and redirected to save any SEO page authority that they might have.
Submitted URL has crawl issue: This message means that Google encountered an unspecified crawling error that doesn’t fall into the other categories. Webmasters can use the URL Inspection tool to check for issues or wait for Googlebot to recrawl the URL.
Indexed, though blocked by robots.txt: This message tells webmasters that Google has decided to index the page, even though directives in the sites robot.txt file may be blocking that page. Google sends this message as a warning because they may not be sure if the block was intentional.
Blocking pages from the index using robots.txt is an obsolete SEO strategy since Google has stopped supporting “noindex” commands in robots.txt, a better strategy is to use on-page meta robots commands. Keep in mind that if Google has indexed a page it is usually because it believes that the content is strong enough to include in its search results.
Submitted and indexed: This is the message that appears for “valid” pages and means that the page submitted has been indexed by Google. This is of course ideal for SEO marketing, since this is the ideal default state.
Keep in mind that number of “submitted and indexed” pages might not always align with what you expect, Google will ignore duplicate URLs, non-canonical URLs, and URLs with parameters (these can be shown in the URL Inspection tool). The number of page’s shown here can sometimes ebb-and-flow with time.
Excluded by ‘noindex’ tag: Google crawled the page but found a robots “noindex” meta tag in the HTML and therefor did not add the page to the index. For SEO purposes meta robots commands are the best way of preventing pages from being indexed, but if the page here was intended to be indexed than webmasters may have to check their CMS settings or remove the tag.
Blocked by page removal tool: This means that the page was removed from the index manually by someone using the URL removal request tool in Google’s Search Console. This is only temporary and even if nothing is done the page will eventually be recrawled and possibly re-indexed after about 90 days. To more permanently remove a page a “noindex” on-page robots command is a better method.
Blocked by robots.txt: This means that the domains robots.txt file has commands that are blocking the page, but that the page has not been “submitted” just that Google has naturally crawled the robots.txt file and found the command.
This does not mean the page won’t be indexed. Because Google has deprecated the “noindex” command in robot.txt a better solution to preventing index is to use the on-page meta robots tag.
Blocked due to unauthorized request (401): The page is blocked to Googlebot by a 401 status code which means that authentication authorization is required to access the page. If this page does need to be indexed for SEO purposes, then the webmaster or site developer should make it so that the content of the page is fully accessible to both users in browser, as well as search engine indexers.
Crawl anomaly: This message in the Google index coverage report means that it encountered some sort of error when crawling the page. It could mean a 4xx or 5xx level response code or that some other problem occurred when trying to load the page. You can use the URL Inspection tool to check for issues.
Crawled – currently not indexed: This is one of the most common messages to see in the index coverage report. It’s important to remember that “crawled” does not mean that the page has automatically been added to Google search results index – it merely means that Googlebot has visited and rendered the page.
One possible explanation is Google has determined that the page is valuable enough to be indexed – perhaps because of a lack of content or thin content. Another reason may be because Google thinks it’s not part of your site’s main content. You can check your page in the URL inspection tool to see if there are any problems with rendering. You can request indexing or add the page to your sitemap in order to indicate to search engines that this page is valuable to your site/business.
You’ll also want to make sure that the content on your page is visible to search engines – for example some JavaScript or Flash content cannot be read by Google.
Discovered – currently not indexed: The URL is known to Google (either from the sitemap or from other means) but Googlebot has not visited or crawled the URL yet. Usually this means that it’s tried to crawl the URL but the site or the domain’s server was overloaded, so Google stopped in order to prevent hampering the site’s performance. In doing this they are giving your site a “crawl budget.”
In most cases nothing needs to be done here if you are checking Google index status for your site. Google will reschedule the crawl and comeback later.
Alternate page with proper canonical tag: In this case Google is aware of the page, but this particular URL has not been indexed because the page’s canonical URL has been indexed instead. For SEO purposes there is nothing to change here and it means that Google is understanding the site correctly.
Duplicate without user-selected canonical: This means that Google has found multiple duplicate URLs for the page, or multiple pages with duplicate content – none of which have been canonicalized. In most cases Google will select its own “canonical” version and index that one – you can check the URL in the URL Inspection tool to see how this page is handled.
Generally no fix is required here since a Google selected canonical works the same as a user declared canonical, but webmasters have the option to set their own canonical if they want to have more control or if they want to index a specific URL.
Duplicate, Google chose different canonical than user: Here the page has a canonical, but Google has chosen another URL as the canonical version instead. If this selection by Google seems okay then webmasters can change the canonicalization to match (or let it be), otherwise it’s best to optimize the site structure to make more sense to search engines or to reduce duplicate URLs.
You should also make sure that the content for “duplicate” pages matches and that the content on your canonical URLs matches the source page. Otherwise Google might not consider it a good canonical.
Not found (404): This page returned a 404 error when requested. This message appears in the index coverage report because Googlebot found a link to the page without a specific request in Search Console or a sitemap, but the link returned a 404.
This probably indicates a broken link somewhere in the content of your site or a broken backlink from another domain. Usually the best solution here is to 301 redirect the link to the closest approximately matching page. This can help to preserve and pass on any associate ranking or page authority for the original page
Google claims that it’s indexing bot may still try to crawl this page for some time, and that there is no way to permanently tell it to forget or ignore a URL – although eventually it will be crawled less often.
Page removed because of legal complaint: In this case a 3rd party complained to Google who removed the content from it’s index, likely because of a copyright infringement or because of one of the other stated violations to Google’s legal rules like phishing, violence, or explicit content.
Keep in mind the stolen, scraped, or plagiarized content also puts marketers at risk of receiving a manual action penalty for thin content. It’s always best to create high-quality original content or give attribution to original sources.
Page with redirect: This message means that the URL shown in the Google index coverage report has a redirect and cannot be added to the index. Google should of course crawl the destination URL without any further action.
Soft 404: Soft 404s can be 404s where the site is designed to return a custom code, “user-friendly” 404 page – like a page that automatically provides options for where to go next. Soft 404s don’t return the corresponding 404 response from the server. Or, a soft 404 can be a page that has thin or no content in Google’s mind and is mistakenly called a soft 404. Depending on the case, they can be a good or bad thing – site owners will want to check their pages to be sure.
If you’re seeing this entry in your index coverage report it means that Google has interpreted the page as a soft 404. But if the page is incorrectly showing as a soft 404, than it might be because the page is rendering mostly blank – make sure that the page’s main content, and main elements are rendering on desktop/mobile and that search engines aren’t being hampered by blocked content, JavaScript, or Flash.
Duplicate, submitted URL not selected as canonical: This means that the page, submitted to Google through a sitemap, was not indexed because Google thinks another URL makes a better canonical version.
The difference between this status and “Google chose different canonical than user” is that in this case, the message is shown because someone has specifically requested this URL to be indexed. Most of the time, for SEO this message is harmless because Google has simply just indexed another duplicate version.
Getting better coverage by submitting a sitemap
The index coverage report in Search Console doesn’t give webmasters an option to directly submit pages to the index or to tell Google all the pages you want indexed.
If webmasters want to get their site indexed there are a few ways to go about it. To get your business listed on Google search results, you can allow indexing spiders to visit your site naturally and go from page to page collecting and rendering URLs for the index. Most of the time this is a fine way of doing it, otherwise you can use the “Sitemaps” report available in the same platform to add a sitemap to Search Console.
Navigate to “Sitemaps” under “Index” on the left site navigation pane. Under “Add a new sitemap” you can add your sitemap URL and then click submit. Of course it may take a few days or even a couple weeks before you start seeing these pages show up in the index coverage report.
Learn How to Improve Your Index Coverage
Contact our team to get more information about the index coverage report for Google search marketing. Our team can help you optimize your site for better search presence and better online growth – plus our RaddBOT SEO technology for site analysis can help you check for crawlability issues by replicating the way that search engines react to your site.